Karma Tracker is a Red Badger project, implemented in Clojure, that tracks contributions to OpenSource projects by the members of an organisation.
Karma Tracker is an internal project at Red Badger, implemented in Clojure, that tracks contributions to OpenSource projects by the members of an organisation. It allows us to keep track of Red Badger's contributions to the OpenSource world. What projects are people at the company contributing to? What languages? What kind of contributions? How do they change over time? These are the questions that we want to answer with Karma Tracker's help.
The following is a detailed description of the architecture of the application and the reasons for it. Even if the application is 100% Clojure this post doesn't require you to know the language. It's more about the functional mindset and best practices from the functional programming world.
Events stream
Karma Tracker (KT) uses the GitHub Events API v3 to monitor the activity of the developers in the organisation. GitHub's API provides ordered sequences of events for each developer. These events contain information about what happened, when and who did it. Example: a PullRequest number 35 has been created by the user lazydevorg on the repository redbadger/karma-tracker on Wednesday, 22nd February 2017 02:39pm. A set of GitHub's events in a time range gives us a picture of what happened in terms of contributions. Events are filtered, removing the ones not needed to generate the report and taking others like: pull requests, issues, comments and reviews. GitHub provides the last 300 (or three months worth of) events for each developer. KT stores the events in a MongoDB database in order to work on them later and have a longer history of the developers' activity.
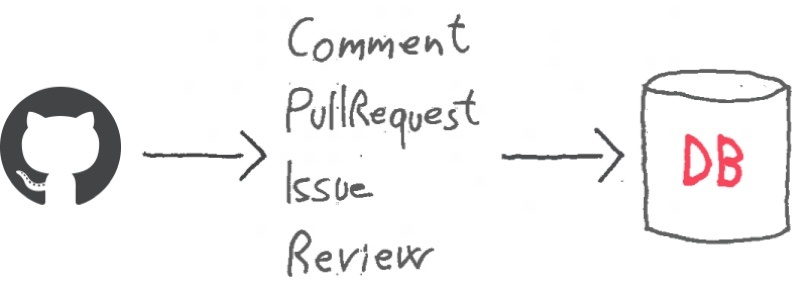
Clojure is perfect for processing streams and transforming data and KT is all about this. The entire process is a map/reduce on GitHub's events that transform them in the final report. Being able to simplify and generalise any problem in a sequence of transformations is the key for writing clear and extensible functional code. The apotheosis is when those sequences of transformations become composable blocks.
Architecture
KT is made of few blocks distributed on three layers. Each of them is independent from the others of the same level. KT's core combines them, creating the flows that execute actions like: download updates, create a report, run the web UI (work in progress) and so on. Having a clear understanding of the logical blocks, their responsibilities and their contracts makes easy to understand how to extend the logic or how to fix a bug.
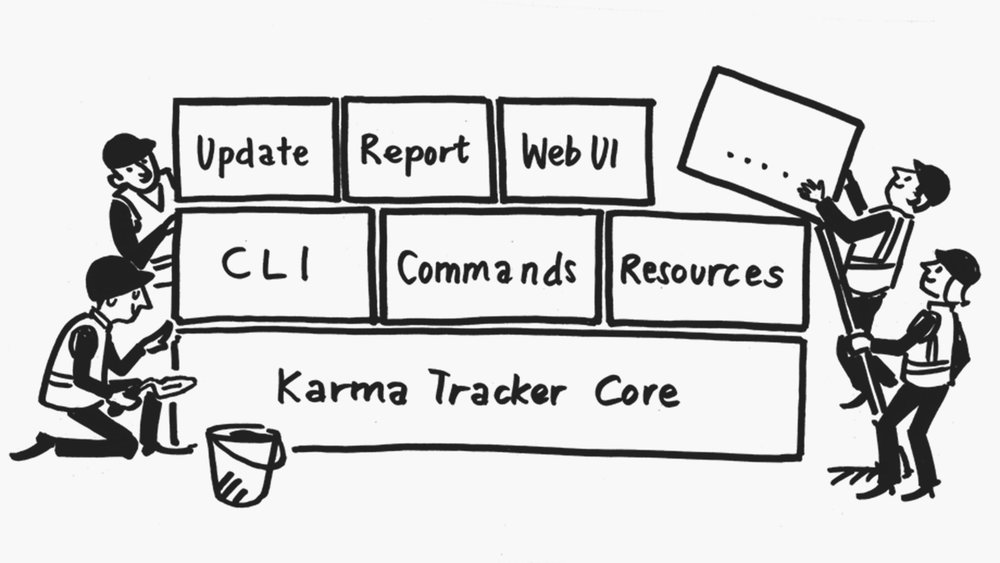
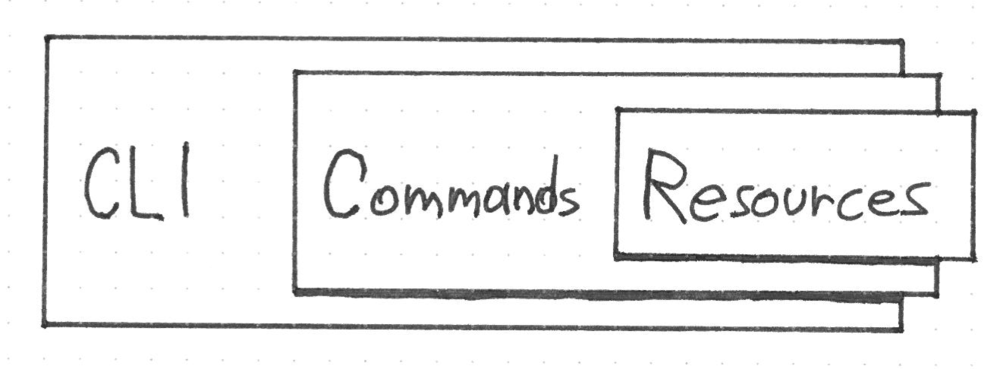
KT's core relies on three main blocks as a base for all the business logic. They are: the Command Line (CLI) block, the Commands block and the Resources block.
The Resources block is responsible for creating a map containing any external resource needed by the application. As of today the only resources needed are the GitHub connection and the events storage. The resources are contained in Clojure's delay instances so that they are instantiated when they are used.
Thus, the only responsibility of the Resources block is to know what resources are needed and what functions are responsible to instantiate them.
The Commands block is responsible to execute commands coming from the command line (and from the web UI later on). It knows what functions to call and what resources are needed. The resources' map is passed as an arguments to the execution function of the Commands block. This way it can pass resources based on the their name not knowing anything about the implementation.
Relying on a different unit to handle the resources makes the Commands block easy to test. The tests are quite simple since they can inject mock resources without any special testing library.
When the command is executed a response is returned so that the calling entity knows about the command's outcome. This make the Commands block composable and independent from the user interface. When a command is executed by the command line then a message in the terminal is shown. When the same command is executed by the web UI then a page is rendered showing the result.
Lastly the CLI block is the one responsible for parsing the command line arguments and creating commands. It is then passed to the execution function that take care of the execution. The execution function is coming from the Commands block and injected in by the KT's core.
When finished, the CLI reads the returned value and show a message in the terminal.
It's important to note that the three main blocks don't have any dependencies among them and so they can be easily composable. Clojure is a LISP dialect. It brings with it the language’s power and it can be very easy to implement complex algorithms. On the other side its power and simplicity has to be used in the right way in order to write good software.
The business logic of the application is built on top of these three main blocks that act as support for all the tasks. KT has two main tasks: the first one downloads new events from GitHub and stores them in the DB, and the second one reads the events from the DB and generates the report. There will soon be a third task that runs the web UI.
Update
The update task uses Tentacles, a Clojure's GitHub library, to retrieve the data needed. First KT retrieves the lists of all the developers in the Red Badger's GitHub organisation then it downloads all the available events for each of them. Tentacles abstract the process of retrieving data in a very nice and functional way exposing lazy sequences of the queried data.
Sounds nice, doesn't it? But what does it mean and why is it important?
Because of the way the GitHub's pagination system works, in order to download the data we should: call the API URL, retrieve the data and check if a next page URL is returned. If so then call the new URL again, retrieve more data and start again. Nothing really complicated in this process but what we want, at the end, is just the list (or sequence) of events of a user. Using lazy sequences allows the application to consume the data while the API requests are made when the data is really needed. Furthermore a lazy sequence can be used with everything that works on sequences (basically the most of the functional world). We can use map on the sequence and while we are getting the new values the lazy sequence is querying new data as soon as it's needed. If we take for instance the first 15 elements of the sequence and the pagination is set to 10 then there will be just 2 requests made to the API but nowhere in the application there is knowledge of that. This is an effective and powerful tool for creating abstractions, separate responsibilities and write clear code. The code that saves the events on the database doesn't know anything about the source of the events. It just receive a sequence and stores every events on the database.
KT makes one more little abstraction that makes the process even simpler. The database layer receives a lazy sequence with the events of all the developers even if the API request are different for each user. The lazy sequence created in KT downloads the events of the first user and when they are finished then it starts adding the events of the second user and so on. The code that consumes the sequence doesn't have any knowledge of that.
Report
The report task generates a HTML file for a given month of the year. It selects the events from the database and apply a map/reduce operation that returns the data to render in the HTML template file.
We tried to make the process as linear as possible to make it easy to understand, easy to change and more productive. We can proudly say that, at the time we are writing this post, we just have one if statement in the whole KT's source code.
The report process is composed of 4 logical blocks: the events fetching, the events normalisation, the events aggregation and the data augmentation. Each of them is a different namespace, completely independent from the others. KT composes them in a single function that fetch events and renders the report.
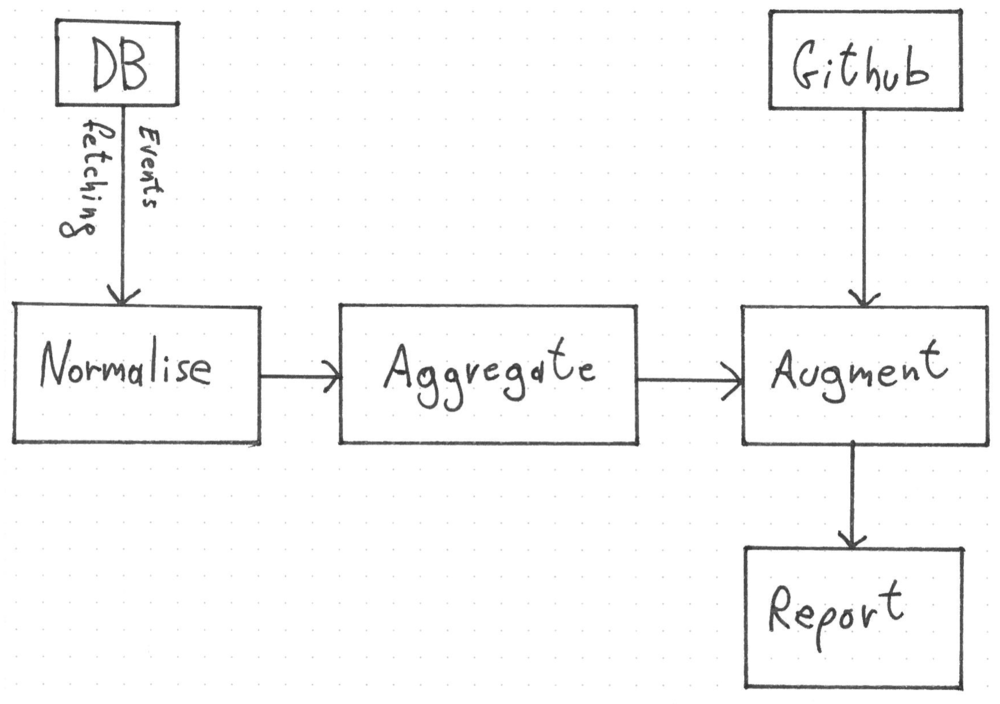
When a report creation is triggered, the events, of the time range specified, are fetched and passed into the normalisation phase. It filters the events not needed and normalises the rest. The normalisation gives us a smaller and a standard set of information that don't depend on the GitHub's event schema.
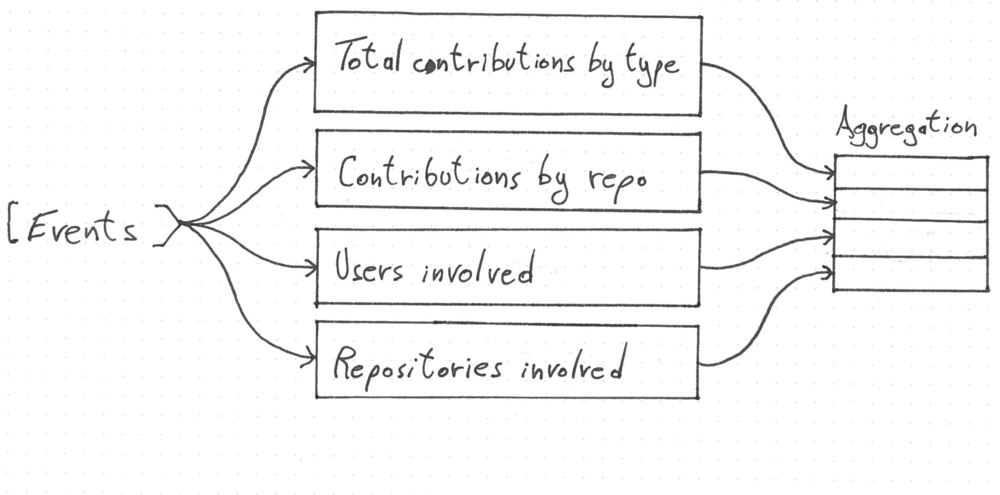
The normalised events are then passed into the aggregation phase. It is composed of few reducers that read the events' stream and generate meaningful information. They extract, for instance, the list of the users and repository involved, the type of contributions for each repository and the totals of all the contributions. Every reducer read the whole event stream and return a map. These maps are then put in a bigger map that is the aggregation result. This stream processing approach brings us a lot of advantages. The business logic is enclosed in clearly defined places (the reducers functions). We can easily plug in additional logic that won't make any difference for the others reducers.
The augmentation phase adds information needed by the report that isn't available in the GitHub's events. As of today KT downloads the languages used for repository involved in the report. Furthermore, this phase, generates additional data from the aggregation like the languages top 10, the top 20 repositories contributions and format the data in a way that can be showed in the report.
This is our first (and still a work in progress) version of KT. Much more work and improvements are going to make it nicer, easy to use and scalable on big data sets. The next incoming feature will be the web UI. A nice and modern dashboard will show you (in real time?) the contributions' to the OpenSource world.
Stay tuned!
Contribute to the Karma Tracker here